
이전 글에 언급했듯 네트워크 계층은 SDN이 도입됨에 따라 Data Plane, Control Plane 두가지 계층으로 나뉘었습니다.
패킷은 SDN에 의해 remote controller에서 전체 라우팅을 결정하고 결정된 라우팅에 맞는 포워딩 테이블이 각 라우터에 뿌려짐으로써 포워딩이 결정됩니다.
여기서 포워딩을 관리하는 계층이 Data Plane, 라우팅을 관리하는 계층이 바로 Control Plane입니다.
그럼 이번에는 네트워크 계층의 control plane에 대해 살펴봅시다!
목차
- 라우팅 프로토콜
- Link State
- 다익스트라(Dijkstra) 알고리즘
- Oscillations posiible Problem
- Distance Vector
- 벨만-포드(Bellman-Ford) 알고리즘
- Count-to-infinity Problem
- Intra AS : OSPF & Inter AS : BGP
- OSPF
- BGP
라우팅 프로토콜
라우팅 프로토콜의 목표는 출발지에서 라우터들을 통해 목적지까지 가는 좋은 경로를 결정하는 것입니다.
여기서 '좋은'은 제일 빠르거나, 제일 비용이 적게 들거나, 제일 혼잡하지 않은 것을 뜻합니다.
보통은 비용이 적게 드는 경로를 선택하게 됩니다.
라우팅 알고리즘 분류
- Static : 라우팅 정보가 천천히 바뀝니다.
- Dynamic : 링크의 비용이 바뀔때 라우팅 정보가 비교적 빠르게 바뀝니다.
- Global : 모든 라우터에 네트워크의 완전한 토폴로지(topology)와 링크 비용 정보가 있습니다.
- → Link State 프로토콜
- Decentralized : 이웃과의 반복적인 계산 과정을 통해 정보를 교환합니다.
- → Distance Vector 프로토콜
이러한 라우팅 프로토콜을 중점으로 자세히 알아봅시다.
Link State
Link state 라우팅 프로토콜은 우리가 사용하는 인터넷의 프로토콜입니다.
더 정확히 말하면 intra-AS 영역에서 사용하는 프로토콜인데, 이는 좀있다 다루도록 하겠습니다.
link state 라우팅 프로토콜은 Global 알고리즘입니다.
즉, 위에서 언급했듯이 각 노드는 전체 노드의 비용 정보를 갖고 있습니다. (여기서 노드란 호스트를 뜻합니다.)
또한 Link State는 다익스트라 알고리즘을 기반으로 합니다.
다익스트라(Dijkstra) 알고리즘
한 노드로부터 전체 노드로 가는 최단 경로를 구할 수 있습니다.

- 출발 노드부터 시작하여 이웃한 노드 중 가장 최단 경로의 노드를 구합니다.
- 그 노드를 노드 집합(set)에 추가하고, 해당 set으로부터 이웃한 노드 중 가장 최단 경로의 노드를 구합니다.
- 이러한 과정을 목적지 노드까지 확장해갑니다.
- 또한 해당 과정 속에서 위 이미지처럼 테이블에 계속 업데이트 합니다.
즉, 한 노드로부터 모든 다른 노드까지 최소 경로를 계산하여 포워딩 테이블을 만듭니다.
다익스트라 알고리즘의 복잡도는
- 남은 전체 노드까지의 비용을 탐색해야 하니
- n + n-1 + n-2 + ... + 1 = n(n+1) / 2 = O(n^2) 입니다.
- 더 효율적으로 고치면 O(nlogn)으로도 구할 수도 있다고 합니다.
Oscillations possible Problem
이러한 다익스트라 알고리즘의 한계점이 있습니다.
바로 진동 가능성(Oscillations possible) 문제입니다.
- 링크 비용이 바뀌면 최단 경로로 패킷이 몰리는 현상을 말합니다.

- 위 이미지를 보면 C → A로 가는 최단 거리가 D로 바뀌면, 패킷이 D로 몰리게 됩니다.
- 그렇다면 congestion이 발생하여 링크 비용이 올라가게 됩니다.
- 따라서 C → A의 최단 경로는 B로 바뀝니다.
- 그러면 또 패킷이 B로 몰려 congestion이 발생합니다.
- 같은 원리로 최단 거리가 D로 바뀝니다.
- 이 것이 반복되어 통과하는 패킷들은 congestion의 저주에서 빠져 나오지 못합니다.
Distance Vector
Distance vector 라우팅 프로토콜은 adhoc network, sensor network 같은 곳에서 사용됩니다.
- adhoc은 각 peer이 노드 역할을 하는데, 이들이 static한 라우터와 달리 dynamic하게 네트워크에 추가되기도 하고 빠져나가기도 합니다.
- 즉 그래프에서 비용뿐 아니라, 노드 자체가 바뀌는 dynamic한 상황인 것입니다.
이러한 distance vector 라우팅 프로토콜은 각 노드가 이웃 노드의 비용 정보만을 가지고 있는 Decentralized 알고리즘입니다.
이는 벨만-포드 알고리즘을 기반으로 합니다.
벨만-포드(Bellman-Ford) 알고리즘
다이나믹 프로그래밍(Dynamic Programming)을 수행합니다.
centrol control이 없이, 네트워크가 계속 변하므로 그때그때 이웃 노드의 변화를 보고 경로를 정하는 것입니다.
아래 이미지의 Dx(y)는 최저 비용을 뜻하며, v는 x와 이웃한 노드들입니다.

벨만-포드 알고리즘은 iterative, asynchronous, distributed한 성질을 가지고 있습니다.

- flow는 위 이미지와 같습니다. 즉, 각 노드는 이웃 노드의 비용 정보가 변화하길 기다리고, 해당 메시지가 오면 비용 정보를 다시 계산합니다.
- 그리고 만일 해당 노드의 비용 정보가 변화한다면 이웃 노드에게 이를 브로트캐스트하여 알려줍니다.
- 이를 iterative하게 하며, 이런 일은 asynchronous하게 발생합니다.
- 또, 중앙 컨트롤러 없이 distributed하게 이것이 처리됩니다.
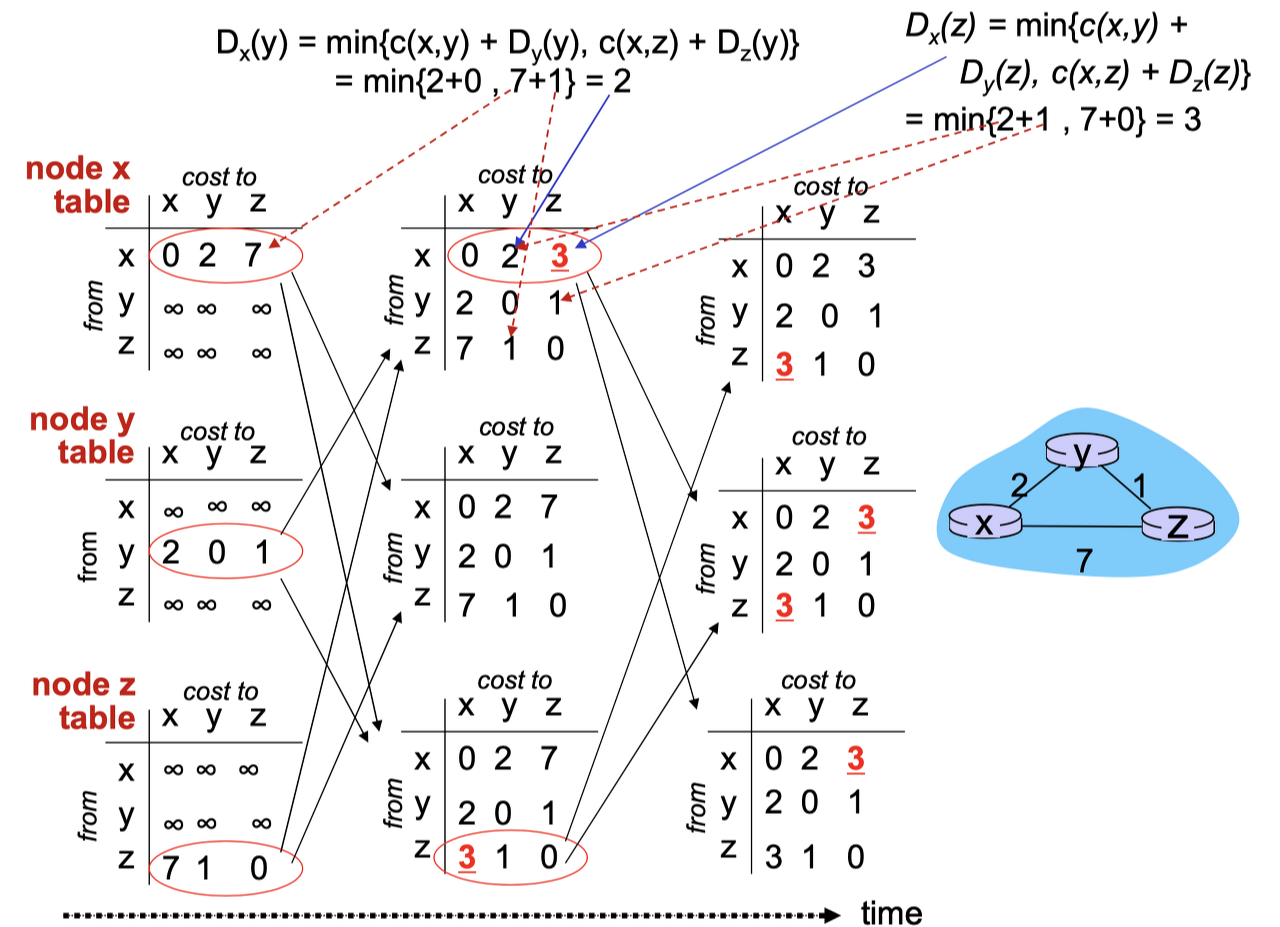
위 이미지를 통해 이해해봅시다.
각 노드는 전체 노드에 대한 최단 경로 테이블을 가지고 있습니다.
물론 이것이 처음부터 옳은 것은 아닙니다. 이웃 노드의 정보 밖에 모르기 때문이죠.
하지만 테이블은 업데이트되면서 이웃 노드에게 뿌려지고, 이웃 노드로부터 메시지가 오면 다시 업데이트됩니다.
이런 일이 반복되다보면, 마지막에 모든 노드의 테이블이 같은 값으로 되는 수렴(convergence)이 일어납니다.
이런식으로 각 노드는 안정적으로 최단 경로를 알게 되는 것입니다.
Count-to-infinity Problem
이러한 distance vector 라우팅 프로토콜 또한 한계점이 있습니다.
수렴이 일어나는데 운이 나쁘면 엄청난 시간이 소요될 수 있는데, 이때 count-to-infinity 문제가 발생할 수 있습니다.
아래 이미지를 통해 해당 문제에 대해 설명하겠습니다.
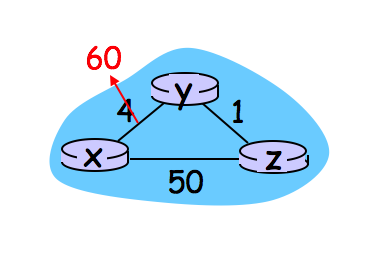
- 위 이미지의 x-y 링크가 60으로 바뀌어도 z는 바로 알아채리지 못합니다.
- 하지만 y는 y → x로 가는 최단 경로가 바뀌었음을 알아채고 y → z → x로 가는 경로를 선택합니다.
- 그런데 이 시점에서 z → x로 가는 최단 경로는 z에 들어있는 정보인 z → y → x 값인 5입니다.
- 따라서 y → x로 가는 최단 경로가 y → z → y → x가 되고, 이는 실제와 다른 값인 6입니다.
- z의 정보 업데이트가 안되었기 때문에 44번의 iteration이 헛으로 돌게 됩니다.
해결 방법은 아래와 같습니다.
- Poisoned Reverse
- 만약 z노드에서 y를 통해 x로 가는 것이 최단 경로라면, z노드가 y노드에게 자신은 x로 가는 비용이 무한대라고 전하는 방식입니다.
- 이렇게 하면 iteration이 줄어듭니다.
- Split Horizen
- 비용 정보를 수신한 노드에 동일 비용 정보를 전송하지 않는 방식입니다.
- Triggered Update
- 네트워크에 변경이 생기면 다음 업데이트 시간을 기다리지 않고 즉시 라우팅 정보를 업데이트하는 방식입니다.
Intra AS : OSPF & Inter AS : BGP
인터넷은 아래 이미지와 같은 구조로 되어있습니다.

각 영역을 intra AS(Autonomous Systems)라고 부르며, 외부 intra AS로 연결되는 라우터를 게이트웨이(gateway)라고 합니다.
인터넷에서 라우팅을 크게 intra-AS 라우팅, inter AS 라우팅으로 나눌 수 있습니다.
- Intra-AS(= intra domain)는 동일한 AS 안에서 라우팅을 하는 것입니다.
- Inter-AS(= inter domain)는 AS들끼리 라우팅을 하는 것입니다.
OSPF
Intra AS에서 쓰이는 프로토콜로, link state 방식을 사용하는 영역입니다.
다익스트라 알고리즘은 한 출발점으로부터 모든 노드까지의 최단 경로를 알 수 있는데, AS 내 모든 노드에서 게이트웨이에 도달하기 위한 최단 경로를 구할 수 있다는 점에서 적합합니다.
만약 AS 자체에 라우터가 너무 많으면?
다익스트라 알고리즘의 복잡도상 비효율적이게 됩니다. 따라서 이를 다시 쪼갭니다.

쪼갠 각 area에서 link state 방식을 사용합니다. (위 이미지의 boundary 라우터는 게이트웨이입니다.)
이러한 hierarchical 라우팅은 테이블 사이즈를 줄이고 업데이트 트래픽도 줄여줍니다.
BGP
Inter AS에서 쓰이는 프로토콜로, distance vector 방식을 사용합니다.
BGP가 AS에게 제공하는 것은 아래와 같습니다.
- eBGP : 이웃하는 AS로부터 도달 가능한 범위를 구합니다.
- iBGP : 도달 가능한 범위 정보를 Intra AS 내에서 모든 라우터에 전파합니다.
도달 가능한 범위 정보, 즉 접근성 정보와 policy를 통해 다른 네트워크까지 도달하기 위한 좋은 경로를 결정할 수 있게 됩니다.
또한 BGP는 prefix와 attributes를 전파합니다.
- prefix : 전파되는 목적지
- attributes
- AS-PATH : 도달할 수 있는 AS의 리스트
- NEXT-HOP : 이웃한 AS로 보내줄 수 있는 게이트웨이 라우터
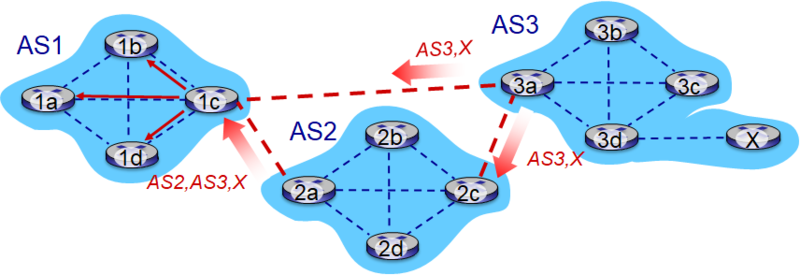
위 이미지를 봅시다. AS1의 1a 라우터는 지금 X에 도달하고 싶습니다.
- AS3의 3a는 eBGP를 통해 AS1와 AS2에 AS3, X 정보를 보냅니다.
- AS2는 iBGP를 통해 해당 attribute(AS-PATH, NEXT-HOP)을 모든 노드에 전파하고, 2a가 이를 캐치합니다.
- 2a는 eBGP를 통해 AS1에게 AS2, AS3, X 정보를 보냅니다.
- AS1의 1c는 X로 가기 위한 경로를 두개 받습니다.
- 여기서 policy에 의해 하나를 선택하고 이를 iBGP를 통해 전파합니다.
- 1a 라우터는 경로를 전달받고, 이를 토대로 포워딩 테이블을 구성합니다.
그럼 선택하는 policy에는 어떤 것이 있을까요?
- shortest AS-PATH
- 내부 AS는 신경쓰지 않고, 외부 AS-PATH 중 최단 경로를 고려합니다.
- closest NEXT-HOP 라우터 : hot potato 라우팅
- 외부 AS는 신경쓰지 않고, 내부 AS에서의 최단 경로를 고려합니다.
Inter AS에서는 이러한 policy에 의해, Intra-AS에서는 link state에 의해 성능이 좌우됩니다!
.
.
.
이 외 네트워크 계층 관련 개념들이 많지만..
이만 마치도록 하겠습니다 😅
만약 중요하다고 생각되는 개념이 있으면 추가할게요!
※ 참조
[네트워크] network layer - control plane
이번에는 network layer의 control plane을 살펴보자. 저번에서 배웠듯 network layer은 SDN이 도입됨에 따라서 두가지 계층으로 나뉘었다. Data plane forwarding : router의 input p...
csmylov.blogspot.com
5.2 Routing protocols
1. link-state routin algorithm - Dijkstra's algorithm D(v) = min(D(v), D(w) + c(w, v)) O(n^2) --> O(nlogn) 까지도 효율 향상 가능 ※oscillations possible - 상기의 알고리즘은 진동 문제를 발생시킬 수..
hddcp.tistory.com