
"성공과 실패를 결정하는 1%의 네트워크 원리 - Tsutomu Tone" 책을 참조하여 작성한 글입니다.
미루고 미루었던 네트워크 공부를 시작했습니다. CS 지식이 부족하여 제대로 공부해보려 해요..
목차
- HTTP Request 메시지를 작성한다
- 웹 서버의 IP 주소를 DNS 서버에 조회한다
- 전 세계의 DNS 서버가 연대한다
HTTP Request 메시지를 작성한다
브라우저는 먼저 입력 받은 URL을 해독합니다.
https://east-star.tistory.com/category/Tech/자바스크립트
위의 URL이 입력되면 아래와 같이 분해하는 작업을 수행합니다.
http: + // + east-star.tistory.com + / + category + / + Tech + / + 자바스크립트
분해된 URL의 각 요소는 아래와 같습니다.
http: + // + 웹 서버명 + / + 디렉토리명 + / + ... + 파일명
- URL의 맨 앞에는 데이터 출어에 엑세스하는 방법, 즉 프로토콜을 기록합니다.
- // 는 다음 이어지는 문자열이 서버의 이름임을 나타냅니다.
- 웹 서버명 이후 문자열은 데이터 출처(파일)의 경로명을 나타낸 것입니다.
'https://east-star.tistory.com' 와 같이 파일명이 생략되어있는 경우?
서버에 따라 다르지만 대부분의 서버가 'index.html' 또는 'default.htm'이라는 파일명을 설정해 둡니다.
그러므로 파일명을 생략하면 설정된 파일에 액세스합니다.
이처럼 URL을 해독하면 어디에 액세스해야 하는지가 판명됩니다. 그러고 나면 브라우저는 HTTP 프로토콜을 사용하여 웹 서버에 액세스합니다.
HTTP란 HyperText Transfer Protocol의 약자로 웹 상에서 서버/클라이언트 모델을 따라 데이터를 주고 받기 위한 프로토콜입니다. 자세한 내용은 다루지 않겠습니다.
먼저 클라이언트에서 서버를 향해 Request 메시지를 보냅니다.
메시지 안에는 '무엇을', '어떻게' 하겠다는 내용이 쓰여있습니다.
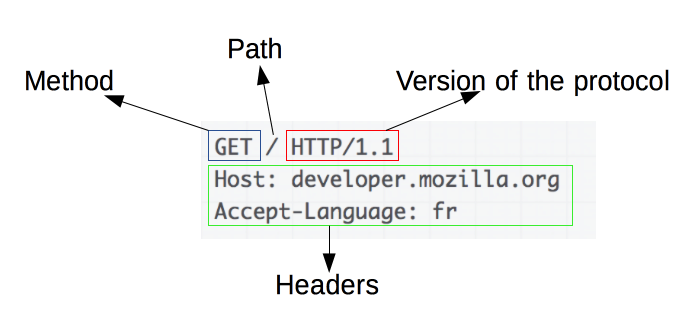
'무엇을'에 해당하는 것을 URI(Uniform Resource Identifier)라고 합니다. 위 이미지에서는 Path에 해당됩니다.
보통 페이지 데이터를 저장한 파일의 이름으로, 예를 들어 '/dir1/file1.html'과 같은 식입니다. 다양한 액세스 대상을 쓸 수 있으며, 이러한 액세스 대상을 통칭하는 말이라 할 수 있습니다.
'어떻게'에 해당하는 것은 메소드(Method)입니다. 이 메소드에 의해 웹 서비스에 어떻게 동작을 하고 싶은지를 전달합니다.
- GET 메소드
- ex) https://test.com/dir1/sample1/user?id=123&pw=456
- 데이터를 읽습니다.
- 파일명이나 프로그램을 나타내는 URI를 덧붙입니다.
- URI 뒤에 데이터를 덧붙여 송신할 수도 있습니다.
- URI 뒤에 덧붙여 송신하는 데이터는 많아야 수백 바이트입니다.
- 따라서 이 정도를 초과하는 데이터의 경우에는 POST 메소드를 사용해야 합니다.
- 그리고 URI 뒤에 덧붙임으로, 데이터가 노출되기에 보안상의 고려를 해야합니다.
- POST 메소드
- ex) https://test.com/dir1/sample1/user
- 서버에 데이터를 송신합니다.
- 입력한 값 등을 서버에 송신할 때 사용합니다.
- 데이터를 Request 메시지의 본문(Body)에 넣어 송신합니다.
- 따라서 GET 메소드에 비해 비교적 큰 용량의 데이터를 송신 가능합니다.
- 또한 URL에 노출되지 않으므로 보안상으로 안전합니다.
(위 메소드들이 가장 많이 사용되는 대표적인 메소드이며, 이를 제외한 여러 메소드도 있습니다.)
메소드 다음에는 위 이미지와 같이 HTTP 버전으로 Request 메시지의 첫번째 행이 완료됩니다.
두 번째 행부터는 메시지 헤더(Headers)라는 행이 이어집니다. 날짜, 데이터의 타입, 언어, 압축 형식, 데이터의 유효 기간 등 부가적인 자세한 정보가 필요한 경우 이를 써두는 것입니다.
이러한 메시지 헤더 뒤에는 송신할 데이터를 씁니다. 이 부분을 메시지 본문(Body)라 하며, 이것이 메시지의 실제 내용이 됩니다.
단 메소드가 GET인 경우에는 메소드와 UIR만으로 웹 서버가 무엇을 할지 판단할 수 있으므로, 본문에 쓰는 송신 데이터는 없습니다.
POST인 경우에는 입력한 데이터 등을 메시지 본문 부분에 씁니다. 이로써 Request 메시지 작성 동작이 완료됩니다!
이 메시지를 보내면 웹 서버에서 Response 메시지가 되돌아옵니다.
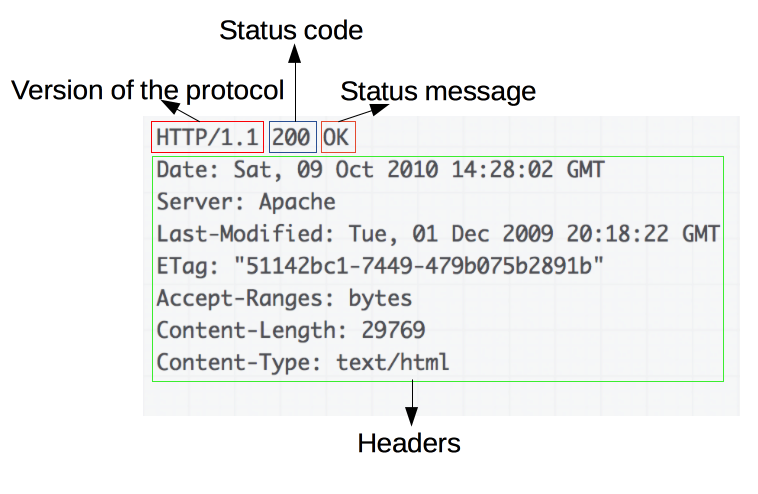
위 이미지에서 볼 수 있듯 HTTP 버전과 상태코드, 상태 메시지로 첫 행을 이룹니다.
응답의 경우 정상 종료했는지, 오류가 발생했는지 등 실행 결과를 상태코드(ex. 200, 404)와 상태코드의 내용을 나타내는 짧은 설명문인 상태메시지(ex. ok, not found)를 통해 나타냅니다.
상태코드
- 1xx : 처리의 경과 상황 등을 통지
- 2xx : 정상 종료
- 3xx : 리다이렉션(무언가 다른 조치가 필요)
- 4xx : 클라이언트측 오류
- 5xx : 서버측 오류
이후 메시지 헤더와 서버에서 송신하는 데이터가 들어있는 메시지 본문이 있습니다.
이때, 메시지 본문의 데이터에 영상 등을 포함한 경우에는 문장 안에 영상 파일을 나타내는 태그라는 제어 정보가 포함되어 있으므로 브라우저는 화면에 문장을 표시할 때 태그를 탐색합니다.
그리고 영상을 포함하고 있는 의미의 태그를 만나면 그곳에 영상용 공백을 비워두고 문장을 표시합니다.
이후 다시 한 번 웹 서버에 액세스하여 태그에 쓰여있는 영상 파일을 웹 서버에서 읽어와서 비워둔 공백에 표시합니다.
- 예를 들어 '/sample1.html'이라는 파일을 읽기 위해 서버에 요청한다면,
GET /sample1.html HTTP/1.1
Accept: */*
Accept-Language: ja
Accept_Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible;
Host: www.test.com
Connection: Keep-Alive- '/sample1.html'의 내용을 응답 메시지를 통해 받고,
HTTP/1.1 200 ok
Date: Wed, 21 Fed 2008 09:19:14 GMT
Server: Apache
Last-Modified: Mon, 10 Feb 2008 12:24:51 GMT
...
Content-Type: text/html
<html>
<head>
...
</head>
<body>
...
<img src="image1.jpg">
...
</body>
</html>- 해당 내용의 태그를 탐색하다 <img src="image1.jpg" > 태그를 만나면, '/image1.jpg'라는 파일을 읽기 위해 서버에 요청합니다.
GET /image1.jpg HTTP/1.1
Accept: */*
Referer: http://www.test.com/sample1.html
Accept-Language: ja
Accept_Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible;
Host: www.test.com
Connection: Keep-Alive- 그리고 '/image1.jpg'의 내용을 응답 메시지를 통해 받습니다.
HTTP/1.1 200 ok
Date: Wed, 21 Feb 2008 09:19:14 GMT
Server: Apache
...
Content-Type: image/ipeg
(여기부터 영상 데이터 = 바이너리 데이터)
...
웹 서버의 IP 주소를 DNS 서버에 조회한다
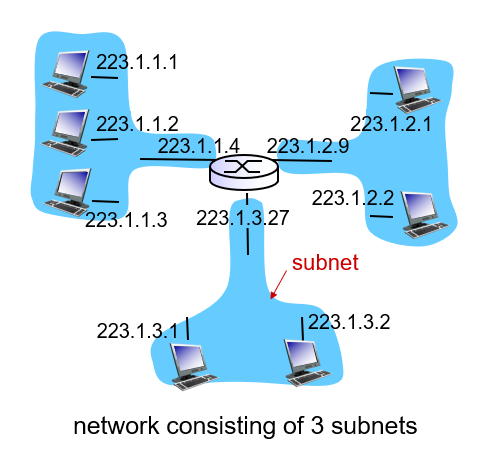
TCP/IP 네트워크는 작은 서브넷을 라우터로 연결하여 전체 네트워크를 완성합니다. 이 서브넷을 주소의 동에 해당하는 것으로 생각하고 '~동 ~ 번지'라는 형태의 네트워크 주소를 할당합니다.
그리고 택배 전표에 받는 사람을 기입하듯이 통신 데이터의 받는 사람 기입란에 액세스 대상의 주소를 기입하여 데이터를 보냅니다.
그러면 라우터가 받는 사람을 보고 이것이 어느 방향에 있는지 조사하여 그 방향으로 데이터를 중계합니다.
이 중계 동작을 반복하면 액세스 대상에 데이터가 도착합니다.
여기서 동에 해당하는 번호를 네트워크 번호, 번지에 해당하는 번호를 호스트 번호라 하며, 이 두 주소를 합쳐서 IP 주소라 합니다.
사람은 이름을 사용하고, 라우터는 IP 주소를 사용한다는 방법이 고안되었고, 현재 이 방법이 정착되어 있습니다.
이름을 알면 IP 주소를 알 수 있다거나 IP 주소를 알면 이름을 알 수 있다는 원리가 바로 DNS입니다. 여기서 이름이 바로 도메인명입니다.
따라서 우리는 도메인명을 가지고 DNS를 통해 IP주소를 알 수 있습니다. 이 IP 주소를 알면 액세스 대상에 데이터를 보낼 수 있는 것!
전 세계의 DNS 서버가 연대한다
인터넷에는 막대한 수의 서버가 있으므로 이것을 전부 1대의 DNS 서버에 등록하는 것은 불가능하겠죠?
그렇기 때문에 정보를 분산시켜서 다수의 DNS 서버에 등록하고, 다수의 DNS 서버가 연대하여 어디에 정보가 등록되어 있는지를 찾아내는 구조입니다.
예를 들어 www.naver.com에 DNS 쿼리가 오면, [Root DNS] → [.com DNS] → [.naver DNS] → [.www DNS] 과정을 거쳐 완벽한 주소를 찾아 IP 주소를 매핑합니다.
즉, [Root DNS], [.com DNS], [.naver DNS], [.www DNS] 와 같은 형식으로 DNS가 분산되어 있다는 것입니다.
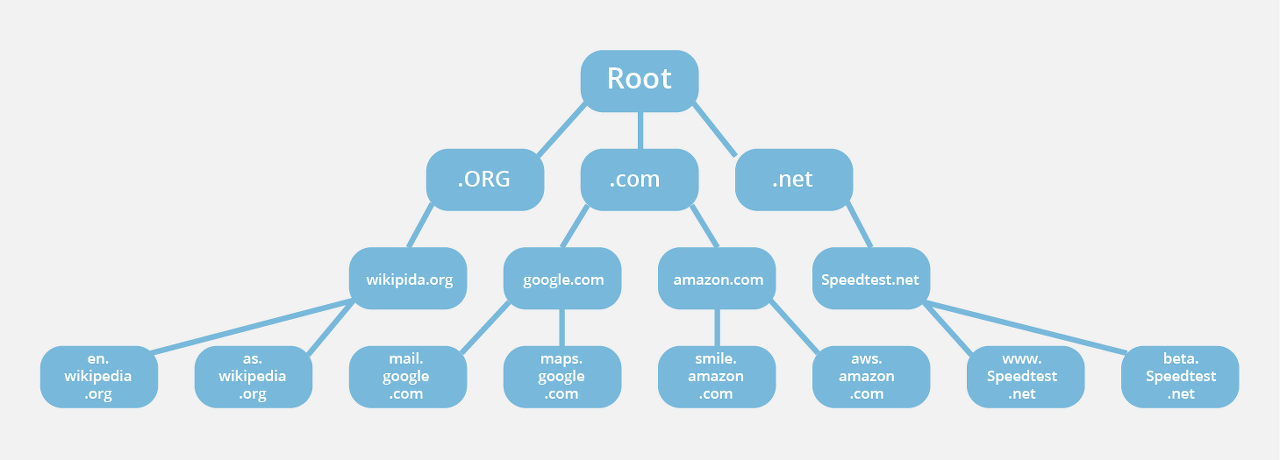
가장 가까운 DNS 서버에 원하는 도메인명에 관한 정보를 조회하고 없다면 루트 도메인부터 원하는 DNS로 내려갑니다.
또한, DNS 서버는 캐시 기능으로 빠르게 회답할 수 있습니다.
하지만 캐시에 저장된 정보가 변경되는 경우도 있으므로, 해당 정보가 올바르다고 단언할 수 없다는 점을 주의해야 합니다!
요약!
입력한 URL을 분해하여 해독하고, HTTP 프로토콜을 사용하여 웹 서버에 액세스한다.
이때 해당 서버의 도메인명을 DNS에 조회하여 서버의 IP 주소를 얻는다.
해당 IP 주소를 통해 라우터를 거쳐 데이터를 송수신한다.
.
.
.
더 자세하고 세부적인 내용들을 많이 제외했습니다. 중요하다고 생각되는 부분만을 요약했어요!
최근 제가 작성한 글들을 보면 너무 많은 것을 한번에 설명하려다 보니 글이 장황해지더라구요..
그래서 앞으로 핵심만을 뽑아 글을 작성하려합니다..
모르는 부분이 있으시면 따로 검색하시거나 댓글 남겨주세요 😅
※ 참조
📖 성공과 실패를 결정하는 1%의 네트워크 원리 (Tsutomu Tone 지음)